- Published on
Law Expression 3
- Authors

- Name
- Piers Concord
- @Piers109uk
Law Expression Part 3: The Prototype
With a data structure selected and prototype prompt written, it was time to start building something a little more concrete!
I wanted to bootstrap 2 things:
- A backend LLM pipeline that would let me run my prompt against laws en masse
- A small web app to interact with the outputs and perhaps edit them
My steps to accomplish this followed those of a typical LLM Specialisation problem: Data management, LLM Management, and LLM Interfacing. I've arranged them as such below.
1. Data Extraction
First I needed to collect data. I decided to scrape the MN State statutes as a starting point (Minnesota is my home state and gets priority!). I extracted the data in this form
export interface IStatuteData {
id: string
url: string
title: string | null
/** section content */
text: string | null
}
Here's the code. It crawls the MN state statutes site using a url pattern matcher to tell which page it's on. When it's on the page of a statute, it snags the data and writes it to a json document.
2. LLM Processing
With the data in-hand, it was time to build an LLM interpreter using the prompts I'd tested with LangFlow. I decided to use Langchain to help with structured outputs using Pydantic - this is useful because getting structured outputs from an LLM can be a pain without a framework to help.
Here's the interpreter code:
class LawInterpreter:
json_logic = read_text("markdown/json-logic.md")
def interpret_law(self, law_object: dict) -> dict:
law_text = law_object.get("text")
# Build the prompt from the json logic spec and the law text
prompt = prompt_template.invoke({"json_logic": self.json_logic, "law": law_text})
# Request a structured output from the LLM (which is validated by Pydanic)
structured_llm = llm.with_structured_output(JsonLogicInterpretation)
# Invoke the LLM with instrumentation (so I can debug later)
response = cast(JsonLogicInterpretation, structured_llm.invoke(prompt, config={"callbacks": [langfuse_handler]}))
res_dict = response.model_dump()
return {**res_dict}
And here's the Pydantic output:
class RuleVariable(BaseModel):
"""A variable used in the JSON logic rule."""
name: str = Field(description="The name of the variable referenced in the rule")
description: str = Field(description="A description of what the variable represents")
class JsonLogicInterpretation(BaseModel):
"""A JSON logic interpretation."""
rule: object = Field(description="The pure JSON logic rule expressed as a JSON object")
examples: list[object] = Field(description="Three examples of data that we could run the JsonLogic rule on")
variables: list[RuleVariable] = Field(description="A list of variables referenced in the rule")
consequences: list[str] = Field(description="The consequences IF the rule evaluates to true, expressed as briefly as possible")
Keeping it simple for now, all that's needed is:
- Build the prompt from the JsonLogic spec I'd made in the previous post and the text of the law I've been given.
- Call the LLM with the prompt, requesting an output with structure
JsonLogicInterpretation - Convert from the Pydantic class back to a dict
A lot more could be done here, but the important part is that the caller of interpret_law doesn't need to know the implementation details. All it's concerned with is giving an input and getting an output, so it will be easy to change the details later.
In future I can try:
- Running json-logic against the rule & examples - if any errors arise, pass them back into the LLM
- A self-review step where another LLM call checks the soundness of the mapping and revises it if necessary
Feel free to see the json-lawgic repo for the full code.
3. LLM Interfacing/Presentation
Now that I could convert as many laws as I liked from text to JsonLogic, it was time to build a web interface. I've never been the artistic sort, but I knew I wanted to be able to:
- Search on the laws
- For a given law, display the title, text, & link, as well as the JsonLogic interpretation, and examples
- Run the JsonLogic interpretation against the examples
To get me up and running fast, I used both v0 and a locally running instance of bolt.new to build me a starting point (I like to point my bolt.new at GPT-4o instead of Claude). Here's the v0 chat (I can't share the bolt chat easily).
I gave Bolt this prompt:
Using NextJs, Tailwind, Typescript, and Minisearch, build me a search widget that I can use to search on a large list of laws. The laws are of the form:
export interface IStatuteData { id: string url: string title: string | null /** section content */ text: string | null }I want to search on the law title. Make the search be on the left third of the screen. Show the results as the user types and when they click a law, display the contents of the law on the right side. Display the first law by default.
While I could have built the UI from scratch, these tools are fantastic for rapid prototyping. Going from concept to visualisation in a minute or two is incredible for knowing whether you like your direction or want to pivot.
Comparing the two:
- Bolt was great for project structure - it actually gives you files and you can ask it to refactor large files into smaller ones (which is great for maintainability)
- v0 was a little more reliable and likely to work than Bolt with GPT-4o
- Bolt regularly errored out and required me to intervene to get it running again
- Bolt gives you more flexibility on tech choices than v0
- But, v0's opinionated tech decisions aren't strictly a bad thing - they are nice tools and I opted to use many of them for this project (Next, Tailwind, Shadcn, etc...)
- Bolt is far more transparent about the dependencies you need than v0
- Both were great for UI visualisation
- My bar is pretty low when it comes to making pretty UIs, but I'd say they both already have me beat on this!
- Neither would be good if I weren't already an engineer
- They both still make junior-engineer level mistakes that could put your project in jeopardy if you follow them blindly
- To accomplish what I wanted, I ultimately still needed to do most of the work, but they saved me a huge amount of time along the way
In conclusion:
- Bolt will be my go-to choice if I want to compare several libraries in a short span of time
- Bolt is also my go-to choice if I need a reference implementation of a library and don't love the documentation that's available
- v0 will be my option if I want to compare multiple UIs and style choices quickly to see what I like most
- My job is still moderately safe (for now): neither tool could be used effectively by a non-engineer yet.
After much back and forth with these, and a bunch of my own coding, I was able to put together a working prototype! (code here if you want to give it a read)
At the time of writing, this is what it looks like
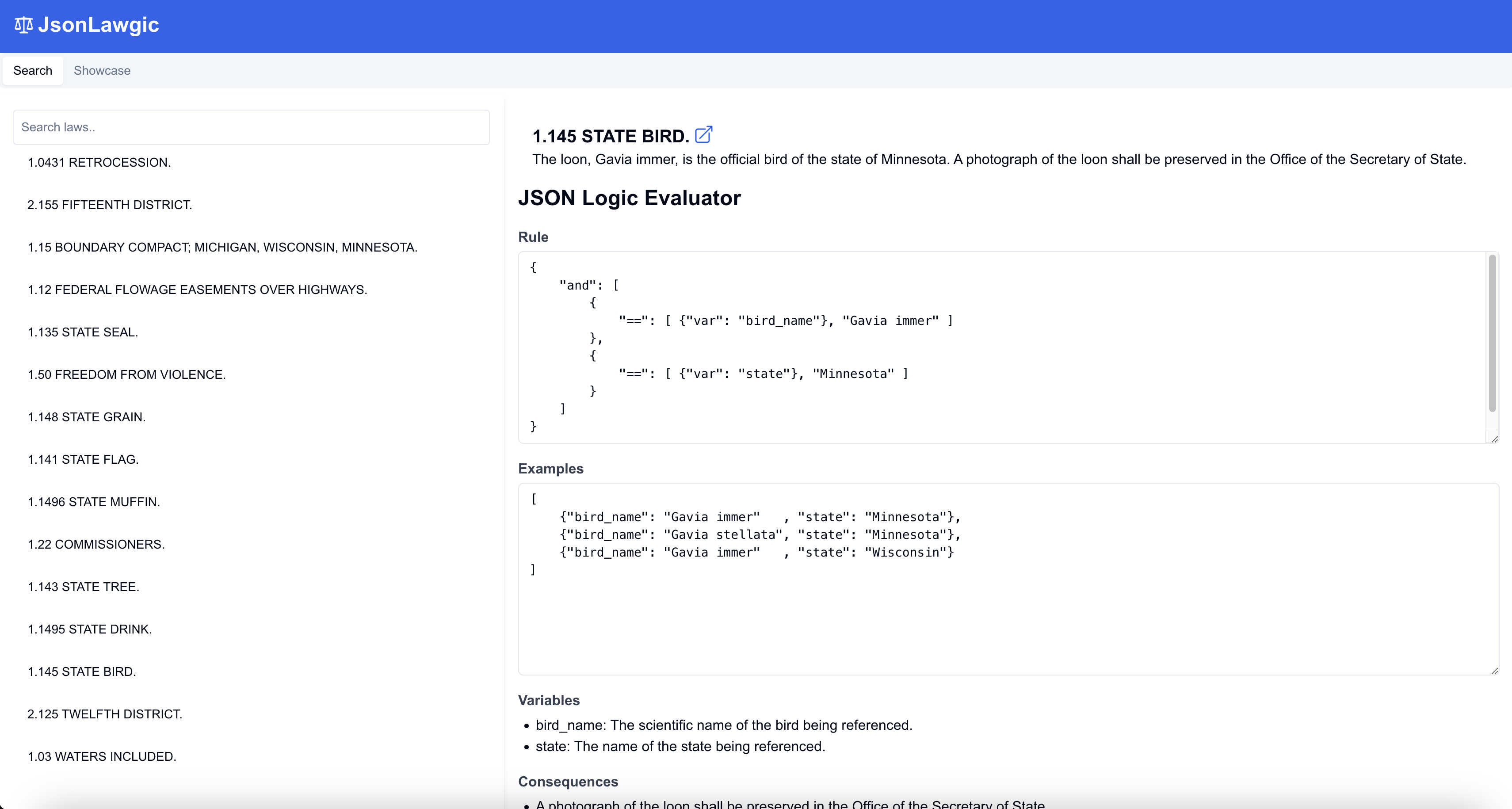
And here's how the examples can be run against the rule:
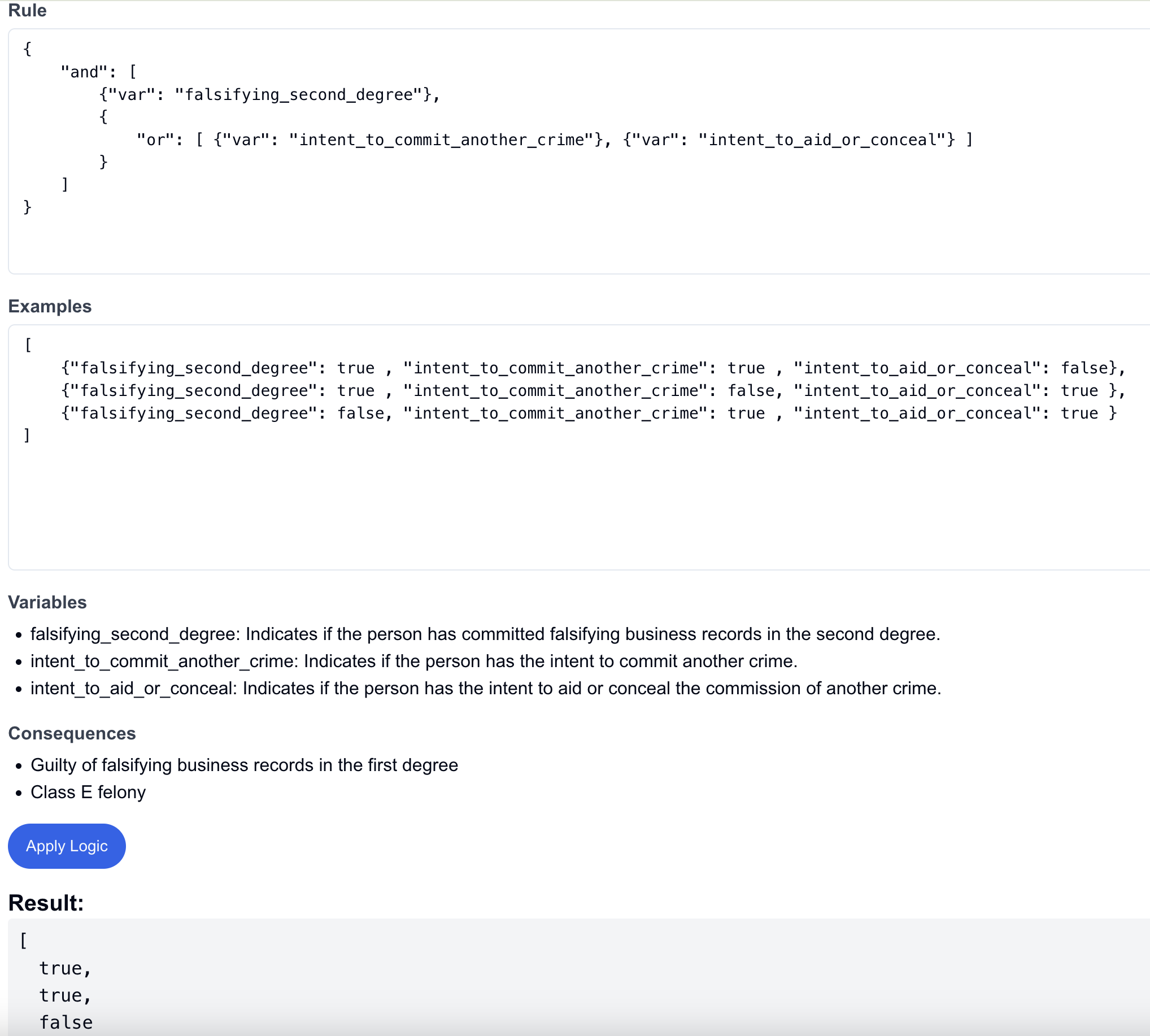
It's possible to search on the laws (I've run the pipeline on about 50, at time of writing), select them, view the law, rule, and examples, and even run the rule on each of the examples and see whether each computes to true or false. It's also possible to edit the rule and examples (but not yet save your edits) and run them again. As a quality-of-life enhancement, I had the LLM outline what the variables are and what the consequences of a "true" value would be.
Since most of the laws run first in the pipeline concern "Minnesota State X" (bird, drink, tree, etc...) rather than more logically-intense concepts, I started putting together a "Showcase" tab to illustrate how the law can be represented by logic for the most applicable examples.
To play around with the app in its current state, I have it deployed here: https://json-lawgic.vercel.app/
Analysis
Seeing as the rule, examples, variables, and consequences are 100% LLM generated, I couldn't help but be impressed by how well the LLM had represented the logic of the law, at least for smaller examples like this. Not only does it create consistently working rules and examples, it's able to provide brief descriptions of the relevant variables and their consequences.
I think this makes for a great recipe: It's not enough to extract pure logic from the law if the user can't understand what that logic represents. But if the LLM can help the user understand what the variables mean, the user will have an easier time working with the logic.
That said, the part I am most excited about is the logic itself. The objective of this exploration can best be described as extracting the least controversial logic from a law and leave the rest open for the usual debate.
This is not to say the logic will always be uncontroversial, or the LLM will always capture it effectively. The LLM is just a tool to scale the solution and do a lot of the legwork. And I understand that sometimes in law, a decision hinges on the interpretation of something seemingly minor (e.g. a comma). So opportunity for debate will remain in the logic. The real magic here is that the logic can be either agreed upon in advance (by interested parties) or debated separately from the variables.
To me, separating the logic and variables is a great opportunity for simplification. If, at any one time, rather than needing to read and understand the whole law, all you need to do is understand the important variables, your work can be decreased substantially because you don't need to hold all the logic in your head at once. This could help make the law more accessible, simplify conversations around it, and even help drafters create legal structures with extra logical rigour.
Next Steps
To get the best use out of this, I'll need to consider the following enhancements:
- Allow the LLM to produce multiple rules from a law rather than just one
- This is necessary because larger laws correspond to multiple concepts - my original mapping of "1 law to 1 rule" was naive!
- Prompt engineering to encourage the simplest possible representation of a law. Also to enhance the logical correctness of the representation
- Pre-filter laws: Not every law needs logic. Some are just declarations.
- Break up larger laws into logical pieces for better LLM performance
- I'd want to try this after allowing the LLM to produce multiple rules - if I'm still dissatisfied with the outcomes for larger laws
- A visual editor for the JsonLogic rules
- One has already been built and open sourced based on JsonLogic, which I could use for inspiration
- For non-technical people, this would be a much preferred form of editing than the current Json interface
- Blawx is a key inspiration for this concept; I don't anticipate feature parity, but it would be interesting to see how close we can get with a format like JsonLogic
- Enhance the connections between the law and the variables
- If we can click a variable and highlight the parts of the law that correspond to it, that would be useful for checking meaning
- Classify the laws (e.g. Deontic specification) and link them to existing data-rich representations like SALI
- Support persisting JsonLogic edits
- If I want to take this from prototype to product, it's going to be necessary for an expert to make alterations to the logical representation of a law and save them (first on a per-user basis, then perhaps in a public forum for discussion)
The App
To see the app in its current state, I have it deployed here: https://json-lawgic.vercel.app/