- Published on
Law Expression 4: Evaluation & Feedback
- Authors

- Name
- Piers Concord
- @Piers109uk
Having reached the proof of concept stage of Json-Lawgic, we've answered some questions and created others:
- Is it possible to use LLMs to express the law as executable code? Yes - Almost without fail, the law can be expressed this way, and the code runs.
- Can this be run as a pipeline en masse across many laws? Yes - The only thing holding me back is the (un)affordability of OpenAI's endpoints - ~$500 to convert all MN state statutes is peanuts for a company, but a lot for me. But we know it can be done.
- What level of quality/fidelity are we getting in the expression? This is partly subjective and remains to be seen.
- What should I build next to prove the concept further? This is hard to decide, and I should gather external feedback to help decide my direction.
- What practical uses exist for this expression? This requires a brainstorm.
In summary, I need to:
- Start building systems to evaluate the quality of my outputs.
- Get feedback from others
- Brainstorm practical uses
LLM-as-a-Judge Evaluation System
Langfuse's Evaluation System
As I sadly don't have a team of lawyers to manually evaluate the quality of my outputs, I have to make do with what I have... Which is cheap LLM labour. I went ahead and integrated an "LLM-as-a-Judge" evaluation system into my traces. While far from perfect, it can give me an idea of quality. It's also a means for benchmarking my changes so I know when I tinker with the system whether I improved or harmed the output quality. Langfuse has a feature that lets you integrate evaluation easily and run it for every trace automatically. I went with this and used the following prompt to control it:
Evaluate the correctness of the JsonLogic interpretation of the law on a continuous scale from 0 to 1. An interpretation can be considered correct (Score: 1) if it includes all the key logic from the law and if every part of the logic presented in the interpretation is factually supported by the law.
Input:
Interpretation: {{interpretation}}
Law: {{law}}
Think step by step.
Which led me to the following scoring within my traces:
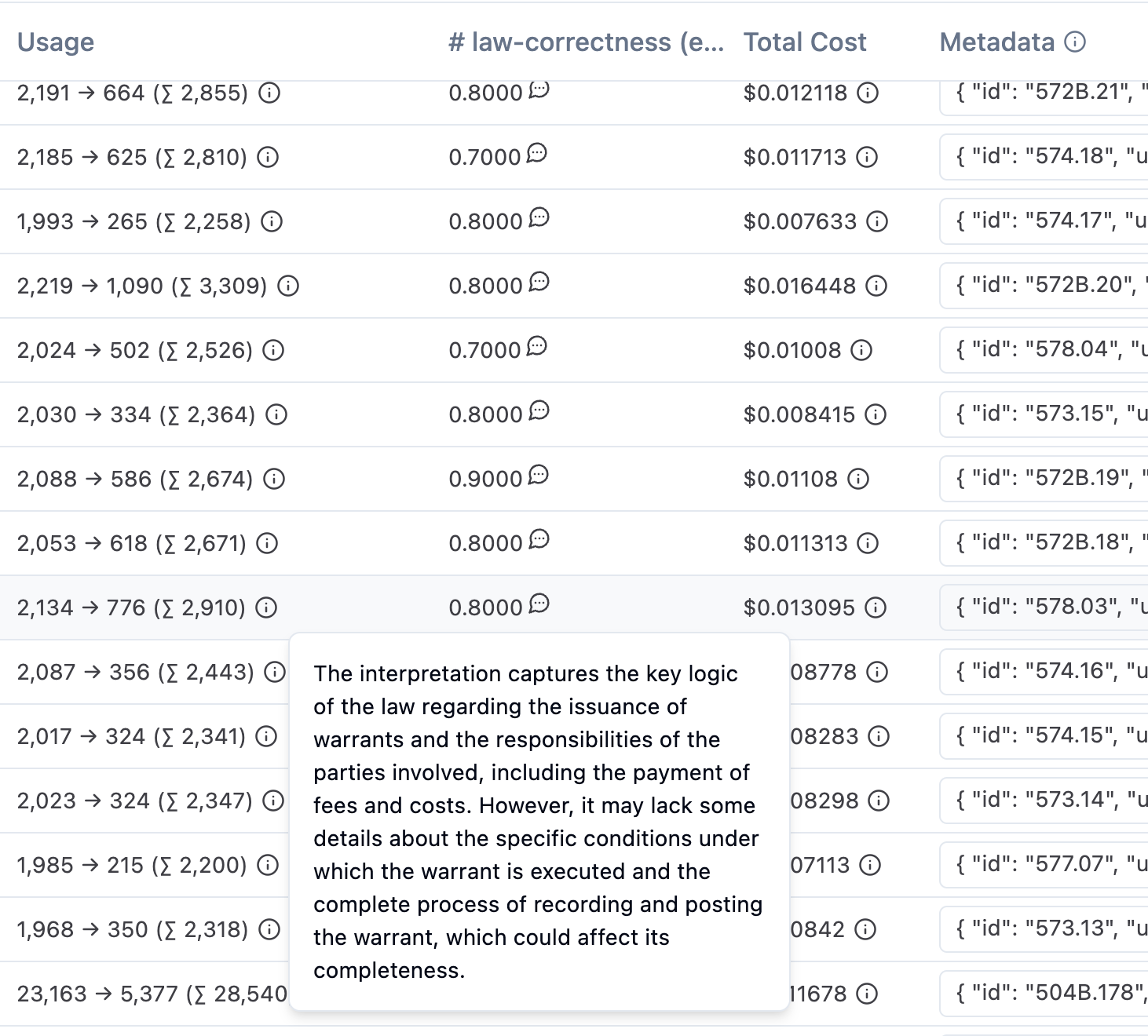
This scoring is much better than nothing, but it would be improved if I could also have a list of specific things the law missed. Nor did I feel I had enough control over the inputs and outputs - it's not clear what exactly is being fed into the model for these evaluations - you don't get to see a trace of the evaluation itself.
So while this is useful if you want to get started quickly, personally I'd recommend building your own evaluation system so you can be certain it's working correctly, and you can request feedback with a structured output.
Building your own evaluation system
Building your own evaluation system that you have control over is dead easy to do. Here's what I did:
class EvaluationResult(BaseModel):
score: float = Field(description="Correctness score between 0 and 1", ge=0, le=1)
reasoning: List[str] = Field(description="A list containing incomplete or incorrect points, if any")
feedback: str = Field(
description="Provide a one sentence reasoning, briefly specify which points were missed, if any",
)
class JsonLogicEvaluator:
def __init__(self):
self.llm = get_model(AIModel.openai_4o).with_structured_output(EvaluationResult)
self.prompt = PromptManager.get_prompt_template("evaluate-interpretation")
def evaluate(self, rules: dict, law: Law, trace_id: str) -> EvaluationResult:
logger.info(f"Evaluating rules for law: {law['id']}")
prompt = self.prompt.invoke({"rules": rules, "law": law})
result = self.llm.invoke(prompt) # {"callbacks": [langfuse_handler]}
eval_result = cast(EvaluationResult, result)
langfuse.score(trace_id=trace_id, name="correctness", value=eval_result.score, comment=eval_result.feedback)
logger.info(f"JsonLogicEvaluator law: {law['id']} score: {eval_result.score} feedback: {eval_result.feedback}")
return eval_result
See the code for more detail.
This code:
- Specifies a structure
EvaluationResultfor the LLM to write to- I explicitly ask for "A list containing incomplete or incorrect points, if any" - in my experience, annotating my fields gives me substantially better results working with LLMs
- Initialises the LLM and prompt, requesting the LLM write to the specified structure with Langchain's
with_structured_output- Behind the scenes, requesting a structured output just follows the native tool calling functionality supported by many models
- Slots the
rulesandlawinto the prompt template and invokes it with the LLM - Sends the score and feedback back to Langfuse, attached to the trace so I can see it just like Langfuse's built-in evaluation system
I like this approach more because:
- I get full transparent control over the evaluator inputs
- I get to specify my own structure for the evaluation - I gather a score and feedback in a similar way, but can request a "list of incomplete or incorrect points" - which is more useful if I want to skim for things entirely lost in the conversion
- I'm not limited to one evaluation (like with the Langfuse free tier) - I can do as many of these as I like
Feedback
I don't believe in building in a vacuum, so I spoke with two experts in the space of computational law. Jason Morris, Rules As Code expert and builder of Blawx, and Damien Riehl, the lawyer-coder whose talk was the original inspiration for converting the law to code using LLMs.
Jason Morris
Jason is a Lawyer, Software Engineer, and expert in Rules as Code. He is a member of the Rules as Code guild and builder of Blawx - user-friendly software for encoding, testing and using rules. Suffice it to say, it would be difficult to find a better person to discuss software that converts the law to code with.
I shared what I built with Jason, including my LLM-based evaluation system (above) and he gave me generally positive feedback and excellent direction for the next steps. In particular, he explained that referring to the conclusion of other rules would cause my implementation to "skyrocket in usefulness".
He also validated my hope that separating "variables from logic" could provide a simpler interface into the law. It turns out my "variables vs logic" comparison can better be described as "rules vs facts" - and that a big problem Rules as Code seeks to solve is allowing individuals to present their facts and get accurate answers about how the rules apply to them. Seeing as an aspiration of mine is that my work can help serve the 92% of unmet legal needs - solving this in a scalable and effective way could be genuinely valuable.
Having had a very pleasant conversation with Jason, I came away with these key takeaways:
- Work out how to "join" multiple rules together in my encoding - I have some ideas for this
- Building an appealing user interface into the tool would go a long way for attracting interest
Jason, if you're reading this, big thank you for the chat, and when you want to start using LLMs to aid Blawx encoding, my inbox will always be open!
Damien Riehl
Following my conversation with Jason, I shared my work with Damien, whose talk on AI in Law and Access to Justice gave me the original inspiration for this project. Damien is a technology lawyer with very broad-reaching experience that covers everything from melody copyright law to automated-vehicle regulation.
I shared my app, goals, and challenges with Damien, including some of my ideas to improve it (e.g. linking variables to the law in the UI), and my current hurdles (e.g. paying the OpenAI bill!). I also thanked him for getting such a fun project on my radar. Damien's feedback was also generally positive, and came with the idea to use an open source foundation model trained on the law instead of OpenAI's GPT-4o. If this provides a means to run the pipeline at scale without compromising on quality, I would be very enthusiastic to set it in motion.
Damien also validated the utility of keeping my encoding as agnostic of the tool built upon it as possible - a big hope of mine is that if I can generate reasonably accurate encodings of the law, engineers with various applications in mind could use it freely.
My next step will be speaking to the creator of KL3M (the open source foundation model trained on the law), with Damien's introduction, and seeing if we can plug it into my existing pipeline!
Damien, thank you again for your vision, direction, and support on this!
Practical Uses
I can see two immediate practical uses that I need to assess:
- Directly programming systems to the outputs
- Integrating the outputs into a tool an LLM can call
What could these look like, and why might they be helpful?
Building directly
First off, there is good precedent already for Rules as Code systems - typically they end up being built by hand and taking a lot of time.
I can envision this kind of work speeding up the delivery of systems wanting to use rules as code - if the rules are already encoded for you, it saves you time and lets you focus on other parts of the system.
The big catch to this is the cost of the encoding, as discussed above. A tradeoff I could accept in the short run would be to enable ad-hoc "law to code" requests within the app. Something for me to consider. If anyone reading this wants a set of laws translated, please reach out and let me know!
Rules as Tool Calls
Hallucinations and a limited context window make two of the largest limitations to LLMs out there. It's simple enough to work around these with a RAG system on top of the law, and many people already have. But even with ground truth provided by RAG, if you feed the LLM too much information at once, it can get distracted and hallucinate. Every RAG request will include a possibility of hallucination, even if the ground truth reduces the likelihood.
Logical reasoning also doesn't fully play to the strengths of LLMs. LLMs are specialised at generating text based the probability of seeing the next word - they are specialised at neither math nor logic. This is why for AI Chatbots needing to perform Math, it's becoming common to equip them with a tool to off-load the actual mathematics. Rather than having the LLM predict the result, let it call a tool that definitively calculates the result instead.
What if we can do the same thing with logic? Encapsulating logic into a tool would provide two benefits:
- You no longer have to trust the logic of the LLM "in that moment" - you are avoiding the risk of "logical error" hallucinations
- You reduce the context window needed
LLMs perform best when you break the problem down into parts. This would do exactly that. If you independently determine that the logic encoded is satisfactory, you can trust the outcome of the tool call.
The downside? You should make sure you're happy that your encoding is complete and correct before using it. I can envision generating an evaluation dataset of law questions and answers to help with this - something to revisit at a later date.
Conclusion
Since I started on this project, I've learned a good deal about why this work is important and now can better see directions I can take it to create something that can meaningfully help people. Here are the next steps I am planning:
- Tool calling: Prototype out a chatbot that can use encoded laws as tools to determine how useful that concept is.
- Rule linking/joining: Re-scrape the MN state statutes, preserving the links this time. Amend my prompt to preserve links between the statutes as part of the encoding. Then code up a way to evaluate & expand on the joining of multiple rules together.
- Investigate open source LLMs: Attempt to scale how many laws I can run my pipeline on by looking into open source LLMs instead of GPT-4o
- Evaluate and enhance: Continue prompt engineering and enhancing the system to build the most accurate logical encodings of the law possible